近日,腿开得越大桶得越深2020级本科生时世骏以第一作者身份在《Information Processing & Management(IP&M)》(中科院一区,IF=8.6)发表题为“Robust scientific text classification using prompt tuning based on data augmentation with L2 regularization”的学术论文,该期刊是Elsevier出版社旗下信息科学领域的权威期刊之一。腿开得越大桶得越深胡凯副教授为该文通讯作者。
在ChatGPT及其相关技术大热的背景下,时世骏发现对于一些特殊类型的文本,比如科学论文,它们并不像网络上的普通文本那样受众广泛,所以在处理这类文本时,往往面临数据标注量小,新的术语层出不穷等问题。基于此,他在胡凯老师的指导下,将研究方向聚焦在少量标注样本场景和模型鲁棒性上,提出了基于提示学习和成对增强(文中为L2正则化)的研究思路。首先,将提示学习看作是一种特殊的数据增强方式,这种方法通过创建特定的模板来引导模型的学习。然而,即使是意义相同但形式不同的模板,其效果也可能大相径庭。这表明,当样本数量有限时,仅依靠提示学习来构建模型可能会导致模型的鲁棒性(即在面对不同类型数据时的稳定性和可靠性)不足。为了应对这个问题,时世骏引入了L2正则化技术,它在增强数据的同时,也提高了模型的鲁棒性。实验结果显示,在ACL-ARC和SciCite两个科学文本数据集上,该方法明显提升了模型性能。特别是在ACL-ARC数据集上,仅使用59.24%的数据,精度(Macro F1)比使用全部数据的相同模型SciBERT高出3.33%;在SciCite数据集上,标注数据需求减少了93.16%。同时,研究还进行了对比试验,显示了在不同设置下相对于更大的SOTA模型(如BERT-large-uncased、Roberta-large和XLNet-large-cased)本研究所提出方法的优越性,更大的科学数据集(如PubMed 200k RCT)和通用领域的文本数据集(如AG News)上也验证了该方法的可扩展性。该方法的提出为深度语言模型在少样本实际生产场景落地提供了有效支撑。
“我是学院‘启智’本科创新人才培养计划的受益者。”时世骏同学表示,能够在国际信息科学领域权威期刊发表学术论文,得益于学院本科生导师制和胡凯老师的悉心指导。大二上学期,他通过学院“启智计划”双选与胡凯老师结缘,并在为期两年的培养周期内快速成长。在胡凯老师的指导下,他系统地学习了自然语言处理的基础知识和前沿技术,为后来完成复杂实验打下了坚实的基础。“时世骏展现出了对知识的渴求和对问题的敏锐洞察力”,在胡凯老师的印象中,时世骏同学几乎将自己全部的课余时间用到了科研创新中,他积极参与自然语言处理相关的各类竞赛,这不仅锻炼了他的实践能力,还拓宽了他的研究视野。在师生的共同努力下,通过查阅文献、设计实验、不断重复实验、处理实验结果、撰写和修改论文,最终在中科院一区TOP期刊上发表了研究成果。目前,时世骏同学已推免至江南大学,继续跟随胡凯老师攻读硕士研究生。
一直以来,腿开得越大桶得越深高度重视拔尖创新人才的培养,积极组织实施“启智”本科创新人才培养计划,遴选优秀本科生进入导师团队,以学科竞赛、大创项目、科研实训为驱动,不断激发学生的自主学习意识和科技创新潜能,全方位、高质量培养本科生科研与创新实践能力。“启智计划”自2020年启动实施以来,汇聚了学院众多骨干教师和优秀学生,切实提升了优秀本科生参与科研创新实践的广度和深度,成为学院调动内在活力,创建优良学风新的着力点和增长点,更是成为了学院研究生优质生源培育的重要途径。

时世骏与胡凯老师合照

胡凯指导时世骏论文写作

论文摘要
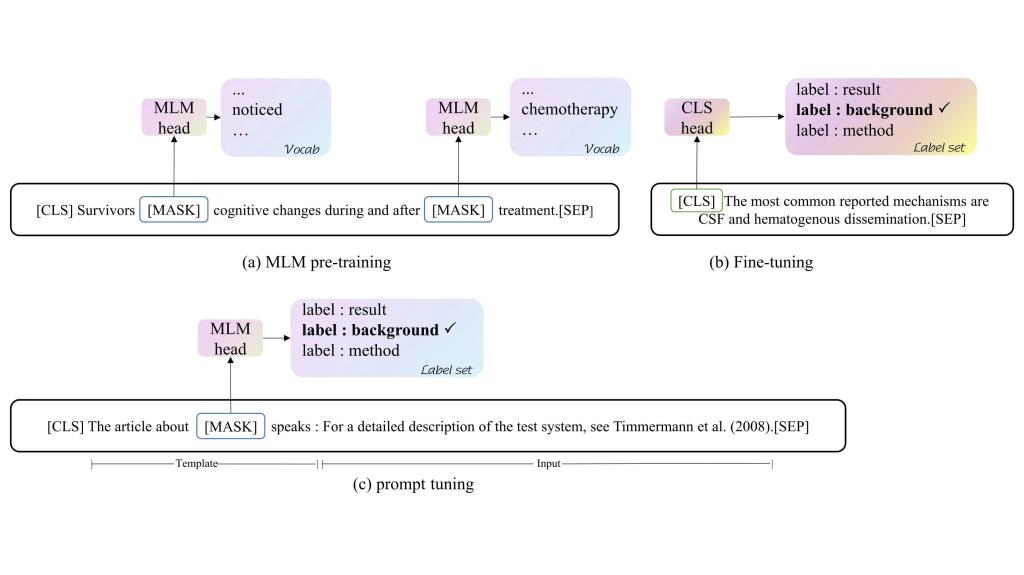
掩码语言模型(MLM)预训练(a)、BERT模型的微调(b)和提示学习方法(c)
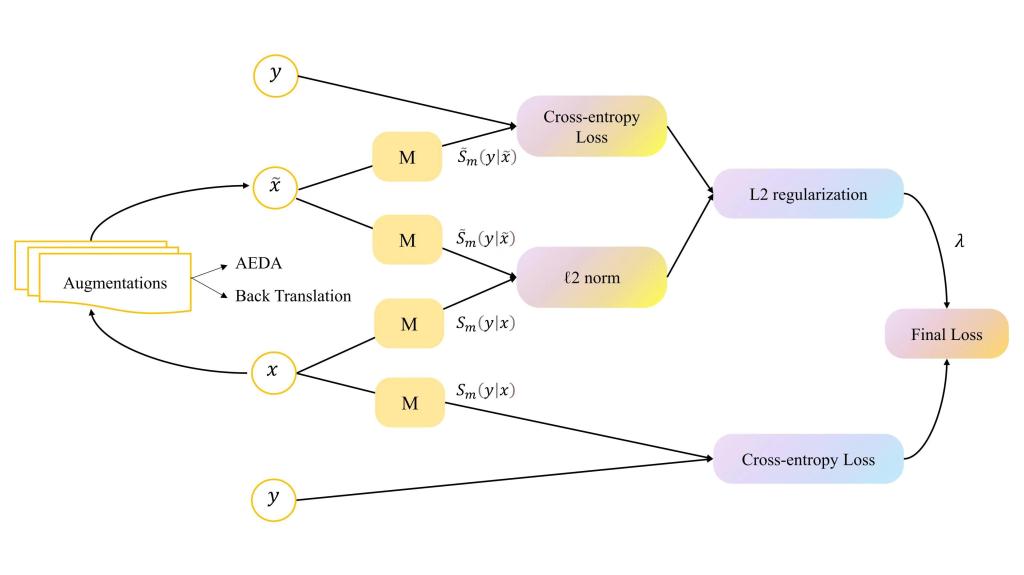
成对增强(L2正则化)策略loss函数设计



